vRealize Automation appliance services not registering
vRA 8.x basics
vRA 8.x health check failing
vRA 8.x Tutorial
A common issue can be vRealize Automation appliance services not registering. This issue is typically noticed after a reboot or unplanned service outtage. The following article is intended to provide a walkthrough of troubleshooting such a scenario.
Unfortunately the vRA catalina.out logfile located under /var/log/vmware/vcac can be quite cryptic in these scenario's and often just reports generic http response response codes.
The service registry can be checked under the vami interface in vRA Settings -> Services tab and also via the component registry URL: https://vRAappliance/component-registry/services/status/current
Based on my experience the main offenders for vRA appliance service registry issues are as follows:
Disk space.
RabbitMQ - internal messaging broker service leveraged by vRA.
vIDM - handles vRA authentication.
vRealize Orchestrator unavailable - can be external or internal.
1.Disk Space
Disk Space can be tricky to pinpoint as the symptoms can be varied, the breakthrough here often boils down to simply remembering to check it.

If a full partition is identified the below command can help drill down to identify precisely whats consuming the space:
du -sh * | sort -hIt will display both files and directories in human readable format and sort based on space consumed. Once a directory is identified you can cd in and run the command again until the offending file(s) is found.
Common causes here are logfiles failing to roll over , excessive DB space consumption, java dump files (.hprof extension). If you are unsure on whether or not files are safe to remove then contact VMware support. In the case of the hprof files I would recommend transferring these off the appliance using winscp and rebooting the appliance once the space has been freed.
Ocassionally the /var/log/vmware/vcac/catalina.out logfile will fail to rotate over , In this scenario you can follow the same approach as for hprof files, winscp the file from appliance to ensure compliance with any logging retention policies in place, remove the original from the appliance to free the space and reboot. Once the vRA services are started a new catalina.out instance will be created.
There is also a known issue with excessive logging of the health service on vRA version 7.3.0. This is fixed in 7.3.1 & later and covered in following KB article
To check the DB size you can connect to postgres database and check table size by running below:
To connect:
/opt/vmware/vpostgres/current/bin/psql vcac postgres
To query for largest 10 database tables:
select schemaname as table_schema,
relname as table_name,
pg_size_pretty(pg_total_relation_size(relid)) as total_size,
pg_size_pretty(pg_relation_size(relid)) as data_size,
pg_size_pretty(pg_total_relation_size(relid) - pg_relation_size(relid))
as external_size
from pg_catalog.pg_statio_user_tables
order by pg_total_relation_size(relid) desc,
pg_relation_size(relid) desc
limit 10;
2.RabbitMQ
RabbitMQ is an internal messaging broker service leveraged by vRA. Its status can be checked at a quick glance under the vRA Settings -> Messaging tab of the vami interface. This interface will show the connection status , process status and connected nodes. This should be checked on each node.
The screenshot below shows the optimal status of a 2 node vRA cluster.

If anything looks amiss here you can simply run a 'Reset RabbitMQ Cluster' operation from the master vRA appliance VAMI interface. This is a safe operation to perform and will not result in the loss of any persistent configuration however it will result in a short period of vRA downtime as the services restart.
If the reset doesnt do the trick then you can check the RabbitMQ logfile rabbit@ApplianceShortname.log located under: var/log/rabbitmq
* RabbitMq has a hard requirement that each vRA appliance is able to resolve eachother by their shortname.
3.vIDM
The vIDM piece can sometimes be responsible for vRA services failing to register. Typically in var/log/vmware/vcac/catalina.out you will see failures related to url's containing 'SaaS' 'Oauth' or other authetication related strings.
The vIDM logfiles to check in this scenario are the horizon.log, workspace.log & connector.log located under: /var/log/vmware/horizon/
For service registry issues focus on horizon.log & workspace.log
For login or directory sync issues focus on connector.log
- In large environments with many tenants the vIDM service can take a long time to initialize. In this scenario you will see the below read timeout errors in the var/log/vmware/vcac/catalina.out logfile
2019-03-02 10:52:55,034 vcac: [component="cafe:catalog" priority="WARN" thread="catalog-service-mainTaskExecutor4" tenant="" context="" parent="" token=""] com.vmware.vcac.platform.rest.client.support.RetriableOperation.call:102 - Exception handled during retry operation with message: I/O error on POST request for "https://vRAappliance:443/SAAS/t/vsphere.local/auth/oauthtoken": Read timed out; nested exception is java.net.SocketTimeoutException: Read timed out. OperationDetails 'Registering [catalog-service] service into Component Registry'
The var/log/vmware/horizon/horizon.log shows:
2019-03-02 12:39:04,597 WARN (tomcat-http--69) [-;-;127.0.0.1;] com.vmware.horizon.rest.exception.resolver.AbstractHorizonHandlerExce
ptionResolver - ResolvedError writting failed [Path:https://vRAappliance/SAAS/API/1.0/REST/system/health] [Handler:public java.lang.String com.vmware.horizon.rest.controller.system.SystemHealthController.getHealth(javax.servlet.http.HttpServletResponse) throws com.tricipher.saas.exception.MyOneLoginException] [Exception:org.apache.catalina.connector.ClientAbortException: java.io.IOException: Connection reset by peer] [Status:500] [MessageKey:generic.exception] - java.lang.IllegalStateException: getOutputStream() has already been called for this response
Checking the health check url below confirms service has not yet initialized as you recieve a connection timeout:
https://vRAappliance/SAAS/API/1.0/REST/system/health
Expected response from this URL in healthy environment:

If you suspect this to be the issue allow time for the horizon service to initialize , the above url can be queried periodically to check this. Once the horizon health check url starts responding issue a restart of the vRA services on each appliance from the command line:
* Note in certain cirumstances, (in particular large environments with over 100 tenants) this may take >30mintues.
service vcac-server restart
The vRA services should now all register. The issue in itself is pretty benign and mostly just tests the patience of the admins however there are certain cicumstances where this issue could become a blocker such as any upgrade or migration scenarios.
If you suspect that the horizon service is taking a long time to initialize open a proactive support ticket with VMware to seek further options. Every environment is different but I would consider anything longer than 15 minutes for horizon to initialize to be excessive.
Options may include increasing the RAM assigned to vRA applainces. This will then be divided up automatically by vRA with the vidm piece gaining a larger share of memory in its heap size config. The elastic search heap size can be increased & other config related optomizations can be made.
- Sometimes following a failover/reboot a lock can be held in the vidm saas schema of the vRA postgres database. In such a scenario you will see below in horizon.log file:
“Error creating bean with name
'liquibase' defined in class path resource [spring/datastore-wireup.xml]:
Invocation of init method failed; nested exception is
liquibase.exception.LockException: Could not acquire change log lock. Currently
locked by fe80:0:0:0:250:56ff:fea8:7d0c%eth0
(fe80:0:0:0:250:56ff:fea8:7d0c%eth0) since 10/29/15”
- Unassigned shards in the elastic search cluster can also impact service registry
To check elastic search health SSH/Putty to each vRA applaince and run:
Check the health of elasticsearch on each node is green.

If the status shows as Red and there is a large number of unassigned shards you can clear these.
*** Note the steps below to clear unassigned shards should only be followed for a single vRA appliance. For environments with more than one vRA appliance raise a ticket with VMware support who will perform the procedure to assign out the shards
1) Snapshot vRA appliance(s) as a precaution.
2) Find current master node, nore the elastic search master node is differnet from vRA cluster master node and is elected dynamically on start up:
curl -XGET http://localhost:9200/_cluster/state/master_node,nodes?prettycurl -XGET http://localhost:9200/_cat/shards | grep UNASSIGNED | awk {'print $1'} | xargs -i curl -XDELETE "http://localhost:9200/{}" 4) Validate again the cluster state:
- One of the more common issue with the vIDM component is corrupt config-state.json files. Although this issue usually affects logins or directory sync not service registry. This issue & resolution is discussed in detail in KB article 2145438
log/vmware/horizon/connector.log file of vRealize Automation will have entries similar to:
ERROR (tomcat-http--14) [;;] com.vmware.horizon.common.api.token.SuiteToken - No keystore file or URL specified.
INFO (tomcat-http--14) [;;] com.vmware.horizon.common.api.token.SuiteToken - Suite token failed to initialize.
WARN (tomcat-http--14) [3002@ESILAB;-;127.0.0.1] com.vmware.horizon.common.api.token.SuiteToken - SuiteToken revocation check failed. The SuiteTokenConfiguration.getRevokeCheckUrl was not set.
INFO (tomcat-http--14) [3002@ESILAB;-;127.0.0.1] com.vmware.horizon.common.api.token.SuiteToken - Initializing keyStore for SuiteToken.
ERROR (tomcat-http--14) [3002@ESILAB;-;127.0.0.1] com.vmware.horizon.common.api.token.SuiteToken - No keystore file or URL specified.
INFO (tomcat-http--14) [3002@ESILAB;-;127.0.0.1] com.vmware.horizon.common.api.token.SuiteToken - Suite token failed to initialize.
INFO (tomcat-http--14) [3002@ESILAB;-;127.0.0.1] com.vmware.horizon.connector.mvc.RestControllerInterceptor - Invalid suite token.
If running vRA 7.3.1 also look out for known issues with hostfile config (56120) & port 40003 not being open in vRA appliance ip tables(56635).
ERROR (tomcat-http--14) [;;] com.vmware.horizon.common.api.token.SuiteToken - No keystore file or URL specified.
INFO (tomcat-http--14) [;;] com.vmware.horizon.common.api.token.SuiteToken - Suite token failed to initialize.
WARN (tomcat-http--14) [3002@ESILAB;-;127.0.0.1] com.vmware.horizon.common.api.token.SuiteToken - SuiteToken revocation check failed. The SuiteTokenConfiguration.getRevokeCheckUrl was not set.
INFO (tomcat-http--14) [3002@ESILAB;-;127.0.0.1] com.vmware.horizon.common.api.token.SuiteToken - Initializing keyStore for SuiteToken.
ERROR (tomcat-http--14) [3002@ESILAB;-;127.0.0.1] com.vmware.horizon.common.api.token.SuiteToken - No keystore file or URL specified.
INFO (tomcat-http--14) [3002@ESILAB;-;127.0.0.1] com.vmware.horizon.common.api.token.SuiteToken - Suite token failed to initialize.
INFO (tomcat-http--14) [3002@ESILAB;-;127.0.0.1] com.vmware.horizon.connector.mvc.RestControllerInterceptor - Invalid suite token.
If running vRA 7.3.1 also look out for known issues with hostfile config (56120) & port 40003 not being open in vRA appliance ip tables(56635).
4.vRO
A specific combination of vRA services have a dependency on the configured vRO instance being available, This can be either the embedded vRO instance running on the vRA appliance themselves or a seperate external vRO instance. The configured instance can be checked in the vRA UI under Administration -> vRO configuration -> Server Configuration
The services dependent on vRO are as follows:
shell-ui-app
011n-gateway-service
Advanced Designer Service
and of course in this scenario at least one instance of the vRO service will also be blank.
If the above combination of services are failing to register then its a tell-tale sign that the configured vRO instance is to blame.
Issue a service restart:
service vco-server restart
service vco-configurator restart
Monitor the Orchestrator logfiles /var/log/vmware/vco/app-server/server.log & /var/log/vmware/vco/configuration/controlcenter.log
You can also run a validate configuration from the vRO control center interface:
https://vROFQDN:8283/vco-controlcenter/
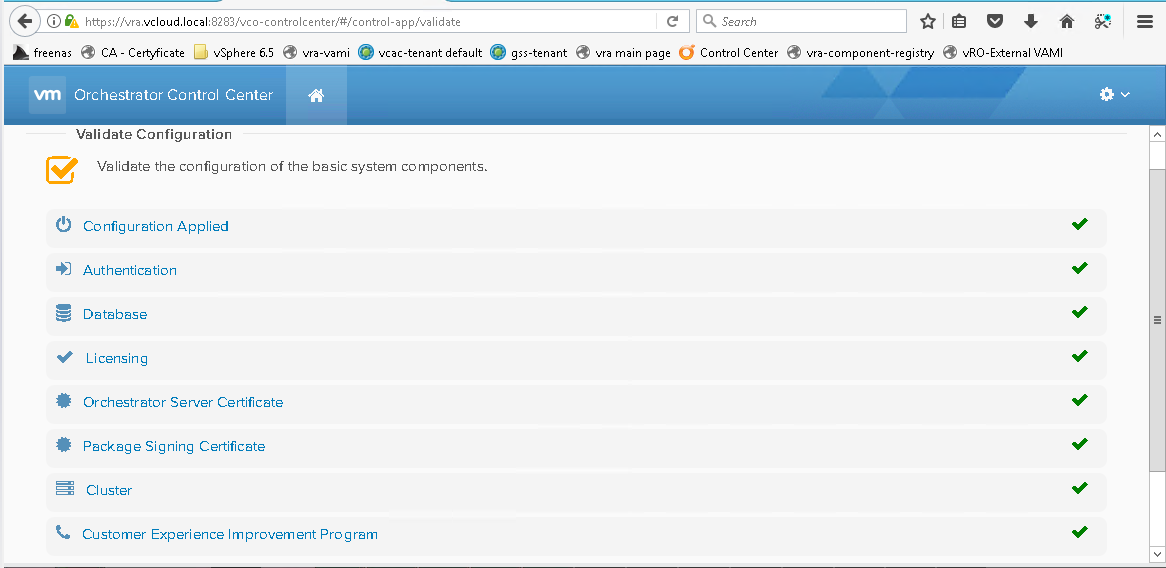
If the authentication is red and cause cannot be determined from logs then snapshot the vRO appliance, document the current authentication settings and perform a reset of the authentication provider:
https://kb.vmware.com/s/article/2151652

If we consider the Big data modernization solutions, then adaptive learning is an excellent way to make it successful.
ReplyDelete