Troubleshooting vRA provisioning failures
First a brief high level view of typical vRA provisioning process
- When a catalog item request is submitted VRA does an initial validation of the request.
- Any approvals are enforced and a reservation check is performed against the IaaS piece to ensure there is a reservation available to satisfy the requested resources.
- Once all these are performed the request gets passed by vRA to the IaaS piece.
- The ContextId can be used to track the request between components, this will be covered in greater detail further on.

- To validate if the IaaS component ever receives the request you can check the repository logfile on the iaas Web servers:
Program Files (x86)\VMware\vCAC\Server\Model Manager Web\logs\Repository.log
- Here you will find the ProvisionAllocatedMachineRequest tags and between these the specification of the request will be outlined including any custom properties.
[UTC:2019-04-22 10:32:14 Local:2019-04-22 11:32] [Trace]: [sub-thread-Id="59" context="6zNLyNKf" token="X4tfAMMl"] ProvisionAllocatedMachineRequest :<?xml version="1.0" encoding="utf-16"?>
<ProvisionAllocatedMachineRequest xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<VirtualMachineId>bc74779b-743a-4238-bf86-b69ac7e42e9b</VirtualMachineId>
....
</ProvisionAllocatedMachineRequest>
- From the IaaS web it will then progress to the Manager service & proxy agents or dems depending on the endpoint.
- Manager service will track the master provisioning workflow VMPSMasterWorkflow:
Program Files (x86)\VMware\vCAC\Server\logs\All.log
[UTC:2019-04-22 10:32:20 Local:2019-04-22 11:32:20] [Trace]: [sub-thread-Id="14" context="6zNLyNKf" token="t8fBhUH0"] vra-test-085: sendEBSMessage4(workflow=bc74779b-743a-4238-bf86-b69ac7e42e9b) for state VMPSMasterWorkflow32.Requested phase PRE event
- vCenter Proxy agent logfile will show the clone workitem:
Program Files (x86)\VMware\vCAC\Agents\Agent_name\logs\vSphereAgent.log
2019-04-22T10:32:49.834Z IAAS vcac: [component="iaas:VRMAgent.exe" priority="Info" thread="2916"] [sub-thread-Id="8" context="6zNLyNKf" token="kn9BCZCq"] Starting : Processing Workitem ID [6c108763-9eb9-4eb7-9a05-5ce936236078] [CloneVM]
2019-04-22T10:32:49.834Z IAAS vcac: [component="iaas:VRMAgent.exe" priority="Debug" thread="2916"] [sub-thread-Id="8" context="6zNLyNKf" token="kn9BCZCq"] [[vra-test-085]] [CloneVM] VirtualMachine.Admin.ID=bc74779b-743a-4238-bf86-b69ac7e42e9b
- The results are then processed back up the chain until they are recieved by vRA
- There is likely also some extensibility built into the provisioning process. The extensibility is handled by the EBS component which runs workflows based on subscription events. Essentially meaning at any point in the provisioning process we can step out and run a vRO workflow.
That covers the overall flow of most typical provisioning requests.
Troubleshooting Failures
Provisioning failures typically occur in one of three component areas: vRA itself, vRO or IaaS. I will first cover the general approach and then guide on the specifics of failures in each component area.
To determine the reason for failure check the requests tab in vRA for the failure reason, note this is named the Deployment tab on vRA 7.5 & higher
The error code responsible for the provisioning failure will ideally have bubbled up through the system and be presented to the end user here.
If the cause of failure is still unclear after reviewing the failure message then check the audit log & monitoring tab in infrastrucure tab. These view are designed to capture any exceptions generated by the system whether the source is vRA, vRO or IaaS.
The state that the machine is in when request is failing will give a good indication of where the problem lies. To determine which state the machine is failing in , the above logs should provide this information as every state change will be logged. If not you can track machine live by searching its name under infrastructure Managed machines tab. This view lists the current state of the machine.
Document the provisioning requests ContextID. The Context ID is used for tracking the request through the various different logfiles & is consistent between all vRA components.
Easiest method I find for getting the ContextID for the provisioning request is to search catalina.out for the relevant request number:
Open the logfile on vRa appliance:
less /var/log/vmware/vcac/catalina.out
Search for request number:
/RequestNumber="155"
Returns our ContextID of "IPIEQ9pc":
[UTC:2019-04-22 09:38:46,125 Local:2019-04-22 09:38:46,125] vcac: [component="cafe:catalog" priority="INFO" thread="queue-pool-executer-2" tenant="gss" context="IPIEQ9pc" parent="IP
IEQ9pc" token="q1DTpFgZ"] com.vmware.vcac.catalog.service.impl.RequestServiceImpl.init:486 - CatalogItemRequest [RequestId="20dc2fa0-0839-4593-8857-6c68d25f897a" RequestNumber="155"
RequestedBy="gss@vcloud.local" RequestedFor="gss@vcloud.local" CatalogItemId="3c2a24fb-abc2-4828-b2b6-813c42ae0bc7" CatalogItemName="Small-Tools" ServiceName="linux" TenantName="gss" SubtenantName="BG-GSS"] : Initializing request at provider
First scenario request fails in vRA..... (Linux appliance side)
If vRA component itself is at fault the provisioning will usually fail right after request submittal. Track the ContextID through /var/log/vmware/vcac/catalina.out for any errors.
See if request tab has provided useful feedback on request failure.
The usual suspects in this scenario are vIDM, Postgres, RabbitMQ or LoadBalancer configuration. For vRA appliance troubleshooting steps see vRealize Automation appliance services not registering
There is also a known issue where the IaaS workflow engine can be blocked if too many machines are stuck in a requested state in the IaaS SQL database, See KB2114385.
*Note while the article is marked as affecting only vRA 7.3 it can also affect higher versions. A fix was included in vRA 7.4 but that only addressed a specific trigger of the issue.
Another issue which can cause machines to become stuck in a requested state is both IaaS manager services running without active failover enabled. While having more than one manager service running is supported on later version of vRA 7 it does have a hard requirement to enable the active failover of the manager service. See official documentation .
In scenarios where both manager services are running and active failover is not enabled the EBS component will end up sending messages to both manager services which do not have awareness of eachother resulting in following messages:
Event Queue operation failed with MessageQueueErrorCode QueueNotFound for queue ’UID′.”
Second scenario request fails in Iaas..... (Windows server side)
If IaaS is at fault the error message should be obvious from the failed request tab. Any IaaS issue’s should be evident in vRA portal under the Infrastructure -> Monitoring -> logs tab as this gathers exceptions from all the IaaS components in a single location.
What to check:
Perform IaaS health-check, check services & log-files in the following order:
IaaS Web (respository.log \ Health check url: https://IaaSWebHost/wapi/api/status/web)
IaaS Manager (all.log\ Health check url: https://IaaSManagerHost /VMPSProvision)
DEMs (all.log)
Agents (AgentName.log)
Machine Customization \ Guest Agent
A common point of failure in IaaS piece is provisioning getting stuck in vRA and eventually timing out during the customize machine/customize OS states.
What to check:
If failing during the customize machine state check vCenter for the “Customization of VM <MachineName> succeeded” event.
vRA is waiting on the above message to be generated before proceeding. If this message is not being generated. Perform manual clone in vCenter using same template/customization spec vRA is leveraging.
Does VM customization succeed for this machine ? If not then issue is outside scope of vRA and is in the vSphere realm. If manual clone customization succeeds then check guest customization logfiles within provisioned VM for any failures(Panther,unattend, /var/log/vmware-imc/toolsDeployPkg.log).
If failing during the customizeOS state check if user is leveraging the relevant OS’s vRA Guest agent. (Supplied for both Linux and Windows)
When leveraging the guest agent it is a requirement that the deployed machine's agent be able to call back to IaaS manger service in order to first gather and ultimately confirm completion of its workitems.
Check the guest agent logfiles for any possible communication issues between provisioned machine and IaaS manager server. A quick test is to verify that the provisioned VM can access the Manager service health check url via web browser. Another common cause can be a lack of trust or expired IaaS manager certificate.
If a service level issue is noticed in IaaS see Iaas Service registry troubleshooting guide.
Third scenario request fails in vRO.....
Normally will manifest itself in the form of a "not found, and possibly deleted before provsioining finished" error message. Alternatively you will recieve a message from the EBs component stating that a workflow run has failed.

If If failure occurs outside of a workflow execution: Test Connection to vRO server from vRA, check vRA /var/log/vmware/catalina.out and vRO /var/log/vmware/vcp/app-server/server.log for cause of failure, check vRO control center and validate configuration.
https://vROFQDN:8283/vco-controlcenter/
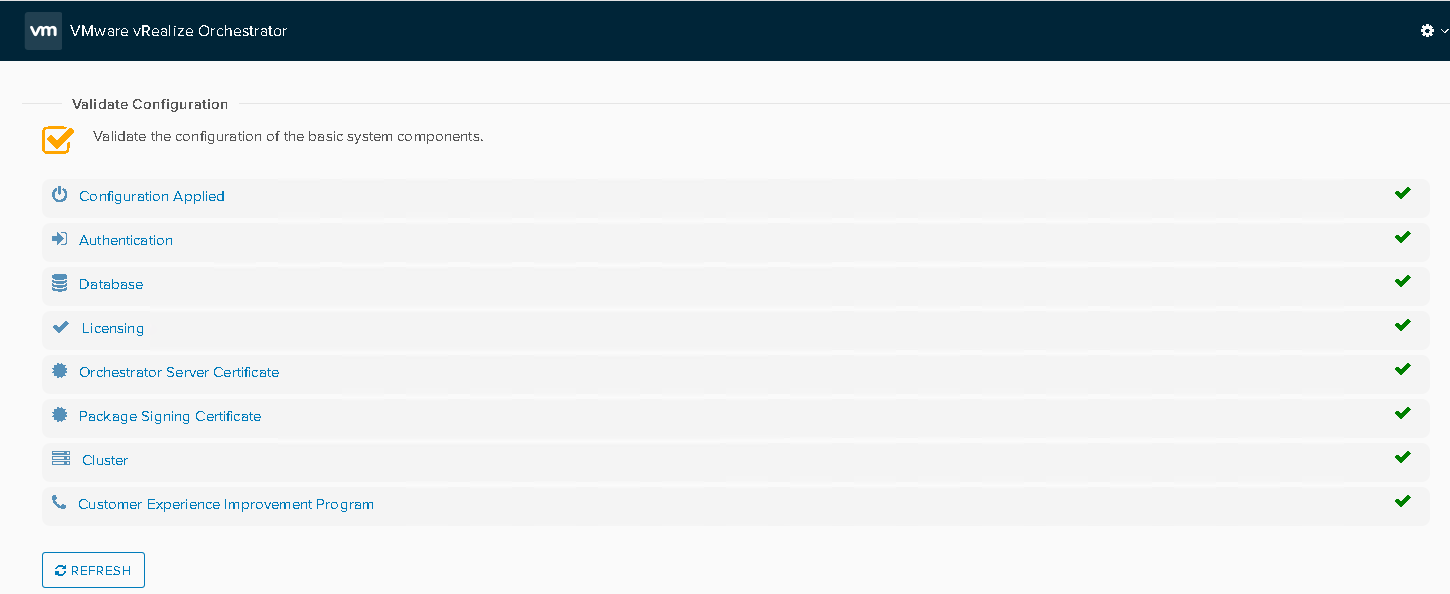
If failure occurs during a workflow execution itself determine whether it is a custom or an out of box workflow being leveraged. If custom WF perform vRO health check & if everything is clear engage the Workflow developer to assist with investigation. If it is an out of box Workflow check vRO logs to determine cause of failure. If the cause of fialure cannot be determined from logfiles then raise a support ticket with VMware support.
Regarding the investigation into why custom code is failing, beyond a basic best effort by VMware support, the onus should be on the workflow developer to provide evidence in terms of why they believe it may be a product issue.
- Determine correct scope , whats affected/not affected. Blanket issue vs intermittent, Identify pattern. Ensure any conclusions drawn here are fact based & reproducible (not coincidental)
- Frequency of the issue, is it intermittent or consistently reproducible. If intermittent how often.
- Determine what changes have been made prior to failure being noticed.
- Track the request using its ContextID; pullout all the relevant extracts into notepad compare these to a previous similar succesful provisioning attempt. In the absence of an error message this will at least assist in detemrining where the trail goes cold.
- For full list of vRA logfile locations see KB 2141175
If you found this article helpful then you may want to take a look at proactive guide for admins wishing to improve the stability, reliability or knowledge of their vRA setup:
Admins-guide-to-keeping-vra-healthy

Comments
Post a Comment