Admins Guide to keeping vRA healthy
Admins Guide to keeping vRA healthy
I've compiled this guide based on my experience troubleshooting countless vRA environments. Whether you are responsible for administering a vRA environment or just looking to get more comfortable with the product in general you are in the right place.
This post will be aimed more towards proactive steps which can be taken to prevent future issues from occurring. However, if you find yourself already in a hole you may want to check out the various troubleshooting post from my 7.x series:
- vRA appliances services not registering
- IaaS service not registering
- Troubleshooting vRA Provisioning failures
The topics & issues discussed below are primarily geared towards vRA 7.x however the majority of the principals can still be applied to vRA 8.x
Check List
- Certificates
- Disk Space
- Understanding Provisioning Process (most crucial in my opinion)
- Load balancer config
- Backup plan
Certificates
One of the most common easily avoidable issues I've seen to date centre around the unforeseen expiry of vRA components certificate. A distributed vRA will have three main certificate components:
- vRA cert itself
- IaaS web certificate
- IaaS manager certificate
The certs including their current expiry dates can be viewed and managed from the vRA VAMI interface certificates tab: https:<vRAFQDN>:5480 -> vRA -> Certificates

There are also internal certificates:
- An iaas solution user certificate which thankfully any time bomb issues have long since been resolved in 7.6 release meaning this should automatically regenerate itself
- The embedded Postgres certificate , sadly a timebomb still exists for this component which will be exactly 5 years since deployment. SSH to vRA appliance & below command will tell you the expiry date, if expired you can follow steps in KB85904 to resolve.
openssl x509 -enddate -noout -in /storage/db/root.crt
!! Note expiry date of each certificate and set a reminder to replace prior to expiry !!
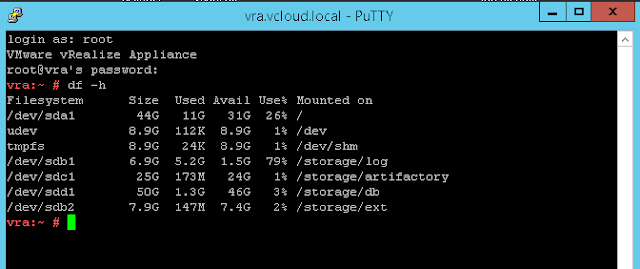
Disk Space
Running out of disk space is another common cause of vRA outages. It can affect the vRA appliance (most common), IaaS windows servers or the SQL server hosting the IaaS SQL database.
The vRA VAMI interface does checks against the vRA appliance and windows IaaS servers (via management agent component). vRA appliance disk space can be viewed on the summary tab, any issues with space on Windows IaaS servers(<5GB space) will be shown on cluster tab:

If it's the vRA appliance disk space that's full it's likely going to be either:
- vRA postgres DB itself
- .hprof file - dump file created when java process crashes (safe to delete)
- A logfile - that's failed to rotate and has grown continuously. (safe to delete)

If it's the IaaS Windows servers a likely culprit could be the Microsoft IIS logfiles, The windows web server component hosting the vRA IaaS repository service. These logfiles are stored under and are safe to delete:
%SystemDrive%\inetpub\logs\LogFiles\W3SVC1
!! For tips on managing these IIS logfiles see Microsoft article !!
Understanding vRA Provisioning Process
Crucial for any admin to understand the provisioning process, due to high level of integration with external & third party components even minor seemingly trivial changes can break things. For example changing the certificate of an external Ipam server , a service account password change. The list is endless but with an in depth understanding of how your vRA provisions its catalogue items you will know when these changes are likely to affect vRA.
!! Important to understand extent of these integrations and the flow of data at each step !!
Some important questions you need to ask yourself here are:
-
What third party software is vRA talking to ? - IPAM/AD/CMDB
- What service accounts are used to communicate with these ?
- What vRO provisioning/decommissioning workflows are running ?
- What components are these workflows looking to communicate with ?
- What dependencies do these vRO provisioning/decommissioning workflows have ?
I won't be able to tell you precisely how your particular vRA is configured to deploy its catalogue items as this is environment specific, for that you would need to contact whoever set up the vRA envrionment and configured the various integrations & catalog items.
I can however provide a general overview of the vRA provisioning process meaning you only need to fill in the gaps and overlay what's applicable in your vRA environment.
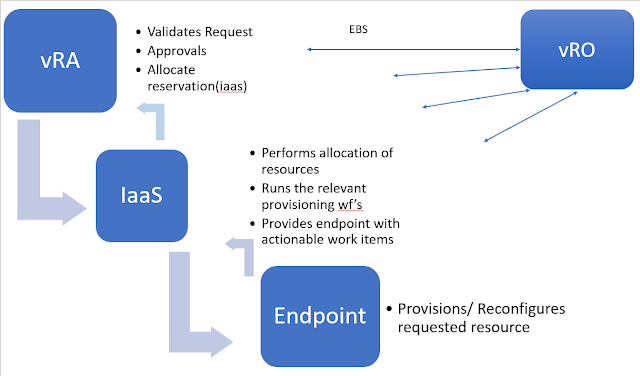
===============Typical vRA Provisioning Process Flow==================
- When a catalog item request is submitted VRA appliances do an initial validation of the request.
- Any approvals are enforced, and a reservation check is performed against the IaaS piece to ensure there is a reservation available to satisfy the requested resources.
- Once these are performed the request gets passed by vRA to the IaaS(windows) piece.
- The ContextId can be used to track the request between components, this will be covered in greater detail further on.

- To validate if the IaaS component ever receives the request you can check the repository logfile on the iaas Web servers:
Program Files (x86)\VMware\vCAC\Server\Model Manager Web\logs\Repository.log
- Here you will find the ProvisionAllocatedMachineRequest tags and between these the specification of the request will be outlined including any custom properties.
[UTC:2019-04-22 10:32:14 Local:2019-04-22 11:32] [Trace]: [sub-thread-Id="59" context="6zNLyNKf" token="X4tfAMMl"] ProvisionAllocatedMachineRequest :<?xml version="1.0" encoding="utf-16"?>
<ProvisionAllocatedMachineRequest xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<VirtualMachineId>bc74779b-743a-4238-bf86-b69ac7e42e9b</VirtualMachineId>
....
</ProvisionAllocatedMachineRequest>
- From the IaaS web it will then progress to the Manager service & proxy agents or dems depending on the endpoint.
- Manager service will track the master provisioning workflow VMPSMasterWorkflow:
Program Files (x86)\VMware\vCAC\Server\logs\All.log
[UTC:2019-04-22 10:32:20 Local:2019-04-22 11:32:20] [Trace]: [sub-thread-Id="14" context="6zNLyNKf" token="t8fBhUH0"] vra-test-085: sendEBSMessage4(workflow=bc74779b-743a-4238-bf86-b69ac7e42e9b) for state VMPSMasterWorkflow32.Requested phase PRE event
- vCenter Proxy agent logfile will show the clone workitem:
Program Files (x86)\VMware\vCAC\Agents\Agent_name\logs\vSphereAgent.log
2019-04-22T10:32:49.834Z IAAS vcac: [component="iaas:VRMAgent.exe" priority="Info" thread="2916"] [sub-thread-Id="8" context="6zNLyNKf" token="kn9BCZCq"] Starting : Processing Workitem ID [6c108763-9eb9-4eb7-9a05-5ce936236078] [CloneVM]
2019-04-22T10:32:49.834Z IAAS vcac: [component="iaas:VRMAgent.exe" priority="Debug" thread="2916"] [sub-thread-Id="8" context="6zNLyNKf" token="kn9BCZCq"] [[vra-test-085]] [CloneVM] VirtualMachine.Admin.ID=bc74779b-743a-4238-bf86-b69ac7e42e9b
- The results are then processed back up the chain until they are received by vRA
- There is likely also some extensibility built into the provisioning process. The extensibility is handled by the EBS component which runs workflows based on subscription events. Essentially meaning at any point in the provisioning process we can step out and run a vRO workflow.
That covers the overall flow of most typical provisioning requests.
!! Most third party integrations are handled in vRO, these objects can be viewed in the vRO client's inventory tab, to resolve issues it's usually just a case or running the relevant update configuration workflow which will allow password updates and trust any new certs !!

Load balancer config
First things first you need to ensure your Load balancer is configured as per the vRA official load balancing documentation.
Pay particular attention to the health monitor configuration as this will tell you what URL's to check if you are getting a bad response at Lb address or if an individual component node is marked as down by the Lb health check.
Important to know the different load balancer addresses & virtual IP's leveraged by vRA and how to troubleshoot when one is not reachable. A distributed vRA will have below Load balanced addresses:
- vRA appliance Lb address
- IaaS Web Lb address
- IaaS Manager Lb address
The Health check address for each is as follows:
1) vRA - LB health check performs a get to /vcac/services/api/health
However, browser will not allow this so best to query url
https://<vRAApplianceFQDN>/vcac/services/api/status
or check vami services tab to ensure each service is shown as REGISTERED:

2) IaaS web - https://<IaaSWebLBUrl>/WAPI/api/status
succesful response will have REGISTERED for "serviceInitializationStatus"tag:
"serviceInitializationStatus":"REGISTERED","serviceName":"iaas-service","solutionUser":null,"startedTime":null}

3) IaaS Manager - https://<IaaSManagerLBUrlnode>/VMPSProvision
succesful response will have ProvisionService for "wsdl:definition":
<wsdl:definitions name="ProvisionService" targetNamespace="http://tempuri.org/">
</wsdl:definitions>

!! Troubleshooting methodology here is the same as with any loadbalanced setup , use process of elimenation to determine where the issue lies. First check individual nodes response , if individual nodes are broken then fix , if individual nodes are ehalthy but lb response is still bad then its an LB issue, either config or otherwise !!
Backup plan
Whilst not the cause of any issue the lack of a decent backup plan can leave one exposed to any number of unexplained events & outages. Backup plans are an essential tool for admins to call upon if and when required. vRA has various components & it's critical to have a frequent recent restore point that can be called upon for each.
Any backup plan should cover the following 3 components:
- vRA appliance(s) - machine level backup will suffice, this covers embedded postgres instance
- IaaS windows server(s) - machine level backup again is sufficient
- IaaS sql database instance - important not to forget vRA iaas sql server database
!! If your vRO's are external then also add those to the list !!
In terms of frequency of backups I would suggest a minimum of daily. If you have a recent restore point for the above 3 components (alongside snapshot of any external vRO's) then there is not much your vRA envrionment cant recover from.

Comments
Post a Comment