vRA 7 appliance runs out of disk space
vRA 7 Appliance runs out of disk space
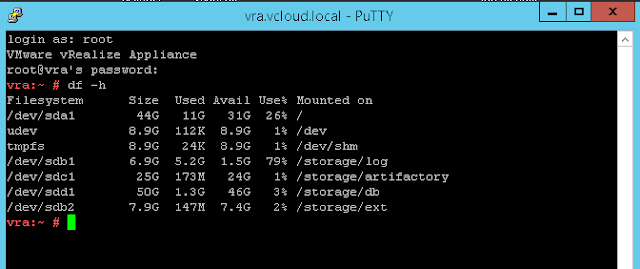
Issues caused by a full vRA appliance disk can be tricky to pinpoint as the symptoms can be varied, the breakthrough here often boils down to simply remembering to check it. To check the vRA appliance(s) partition disk usage, SSH/Putty to vRA appliance login with root user and run:
df -h
If a full partition is identified the below command can help drill down to identify precisely what's consuming the space. It will display both files and directories in human-readablecd format and sort based on space consumed. Once a directory is identified you can cd in and run the command again until the offending file(s) is found.
du -sh * | sort -h
This process can be repeated drilling down further into filesystem until the offending files or files are found.
**Top Tip**
As a first step if cause cannot be easily identified & to alleviate any pressure or to prevent filesystem corruption I would recommend adding disk space to vRA appliances by following VMware Kb article vRealize Automation appliance runs out of disk space (2133183)
These steps are specific to the SDB2 partition that holds the vPostgres database. To increase the disk space in other partitions, simply update the commands to match the correct location.
In later vRA 7.x versions checks for disk space & database size have also included in the VAMI interface: https://vRAFQDN:5480 (root user credentials)
Most common causes
** As best practise precaution before removing any files or DB content first ensure a full backup is taken of vRA appliance(s) !! **
- Unchecked Database growth
- Core or java hprof dump files
- logfiles failing to rotate
1.Unchecked Database Growth
The vRA appliance comes with an embedded Postgres instance which can occasionally experience unchecked growth. To check the DB size you can connect to postgres database.
- Putty/SSH to vRA appliance as root user and run:
/opt/vmware/vpostgres/current/bin/psql vcac postgres
- To query for largest 10 database tables in vRA database run below select query:
select schemaname as table_schema,
relname as table_name,
pg_size_pretty(pg_total_relation_size(relid)) as total_size,
pg_size_pretty(pg_relation_size(relid)) as data_size,
pg_size_pretty(pg_total_relation_size(relid) - pg_relation_size(relid))
as external_size
from pg_catalog.pg_statio_user_tables
order by pg_total_relation_size(relid) desc,
pg_relation_size(relid) desc
limit 10;
2.Core or java hprof dump files
java .hprof files are essentially the contents of a java processes running memory dumped to a file whenever it crashes, depending on the amount of memory consumed by the service at the time these files can be quite large.
To search for any Java hprof files, from root directory run:
find / -name *.hprof
Core dump files are similar to java hprof files and are written for post mortem of crashed processes.
As the file(s) are written after the program crashed, they can safely be removed at any time.
To search for any core dump files, from root directory run:
find / -name core.*
If crashes are a recurring issue and you wish to ahve them root caused then use winscp to copy off dump or hprof fiels prior to removing otherwise simply remove them:
rm <path to file>
For example
rm /storage/ext/core/core.977684
3.Logfiles failing to rotate
Occasionally logfiles can fail to roll-over resulting in unchecked growth of the current active log file most commonly for vRA /var/log/vmware/vcac/catalina.out or for vRO /var/log/vmware/vco/app-server/server.log.
The disk space commands at beginning of article will help identify this scenario.
- To resolve stop the service relevant to the logfile:
VRA: service vcac-server stop
vRO: service vco-server stop
- If you wish to keep the logs for auditing, security or general troubleshooting purposes then use WinSCP to copy the file off, otherwise simply remove:
rm <path to logfile>
For example:
rm /var/log/vmware/vcac/catalina.out
- Start again the relevant service
VRA: service vcac-server start
vRO: service vco-server start
It may not always be a single large logfile responsible for consuming the space, it may be the case that log rotation is failing to remove older already compressed logfiles from the file system. vRA stores old logfiles as compressed .bz2 file extension types
If you find the cause of the issue is related to an abnormally high amount of compressed old .bz2 logfiles these can also be removed, but again if auditing is a concern then best to WinSCP the file off first.
rm *.bz2
Hope you find this page useful if you have any queries or feedback feel free to drop a comment below

Comments
Post a Comment